
- Project 27, Projects
A framework designed to segment multi-band galaxy images by combining morphology and spectral information. The method first uses a starlet-based multiscale decomposition to identify the main galaxy structure, and then groups pixels according to the similarity of their spectral energy distributions across the available bands.

- Project 26, Projects
Here we present AT2022zod, an extreme, short-lived optical flare in an elliptical galaxy at z = 0.11, residing within 3 kpc from the galaxy’s centre. Its luminosity and ∼30-day duration make it unlikely to have originated from the host galaxy’s central supermassive black hole (SMBH), which we estimate to have a mass of ∼ 108 M⊙. Assuming that the emission mechanism is consistent with known observed TDEs, we find that such a rapidly evolving transient could either be produced by a MBH in the intermediate-mass range or, alternatively, result from the tidal disruption of a star on a non-parabolic orbit around the central SMBH.

- Project 25, Projects
ELEPHANT represents an effective strategy to filter extragalactic events within large and complex astronomical alert streams. There are many applications for which this pipeline will be useful, ranging from transient selection for follow-up to studies of transient environments. We find that less than 2% of all analyzed transients are potentially hostless. Among them, approximately 10% have a spectroscopic class reported on TNS, with Type Ia supernova being the most common class, followed by SLSN. Among the hostless candidates retrieved by our pipeline, there was SN 2018ibb, which has been proposed to be a PISN candidate; and SN 2022ann, one of only five known SNe Icn. When no class is reported on TNS, the dominant classes are QSO and SN candidates, the former obtained from SIMBAD and the latter inferred using the Fink ML classifier.
- Project 24, Projects
We emulate photometric SN Ia cosmology samples with controlled contamination rates of individual contaminant classes and evaluate each of them under a set of classification metrics. We then derive cosmological parameter constraints from all samples under two common analysis approaches and quantify the impact of contamination by each contaminant class on the resulting cosmological parameter estimates. We observe that cosmology metrics are sensitive to both the contamination rate and the class of the contaminating population, whereas the classification metrics are insensitive to the latter. We therefore discourage exclusive reliance on classification-based metrics for cosmological analysis design decisions, e.g. classifier choice, and instead recommend optimizing using a metric of cosmological parameter constraining power.
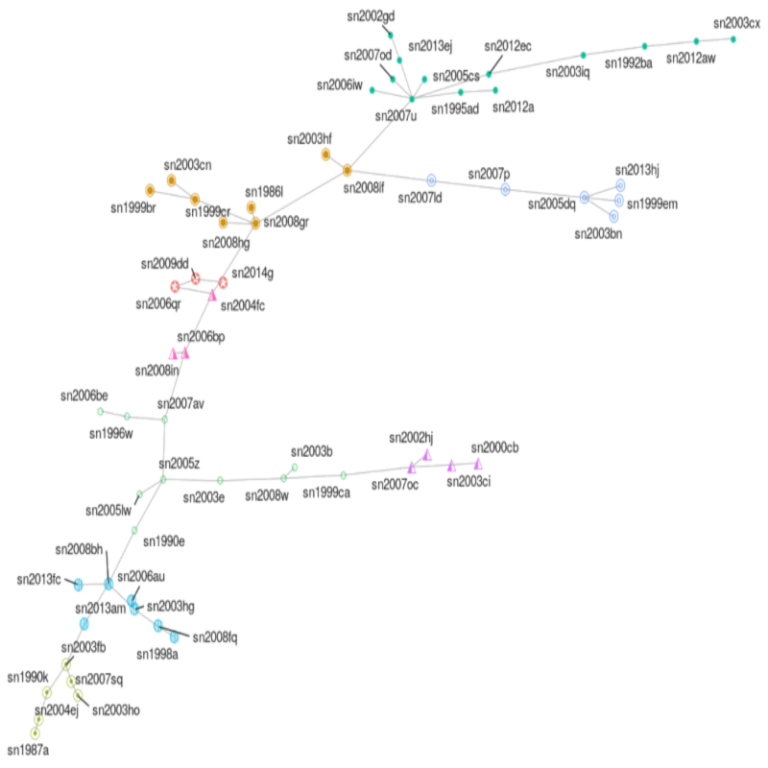
- Project 23, Projects
This work presents new data-driven classification heuristics for spectral data based on graph theory. As a case in point, we devise a spectral classification scheme of Type II supernova (SNe II) as a function of the phase relative to the V -band maximum light and the end of the plateau phase. Our classification method naturally identifies outliers and arranges the different SNe in terms of their major spectral features. The automated classification naturally reflects the fast evolution of Type II SNe around the maximum light while showcasing their homogeneity close to the end of the plateau phase. The scheme we develop could be more widely applicable to unsupervised time series classification or characterization of other functional data.
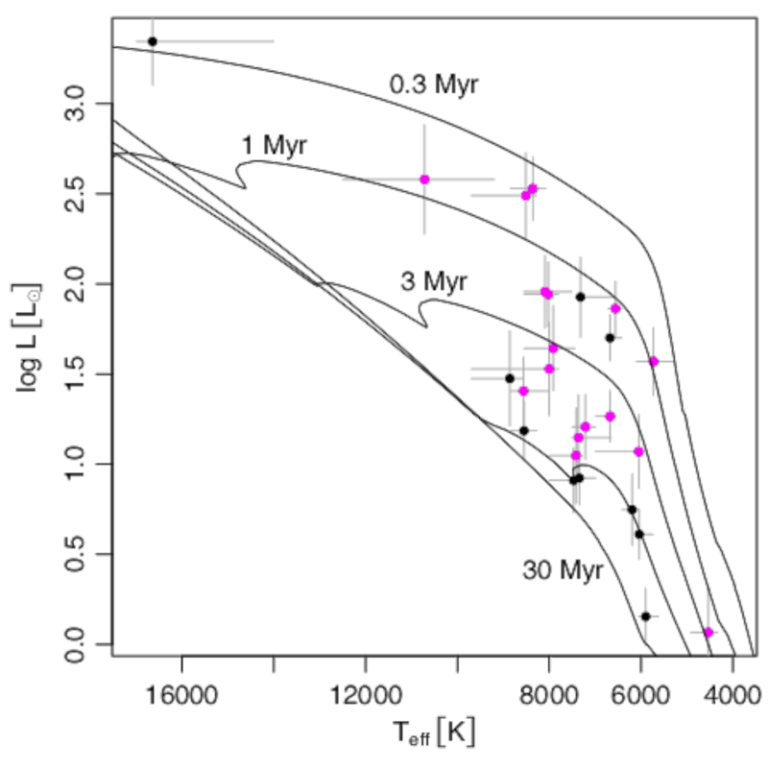
- Project 22, Projects
The Spitzer/IRAC Candidate YSO (SPICY) catalog is one of the largest compilations of such objects (~120,000 candidates in the Galactic midplane). Many SPICY candidates are spatially clustered, but, perhaps surprisingly, approximately half the candidates appear spatially distributed. To better characterize this unexpected population and confirm its nature, we obtained Palomar/DBSP spectroscopy for 26 of the optically-bright (G<15 mag) "isolated" YSO candidates. We confirm the YSO classifications of all 26 sources based on their positions on the Hertzsprung-Russell diagram, H and Ca II line-emission from over half the sample, and robust detection of infrared excesses. This implies a contamination rate of <10% for SPICY stars that meet our optical selection criteria.
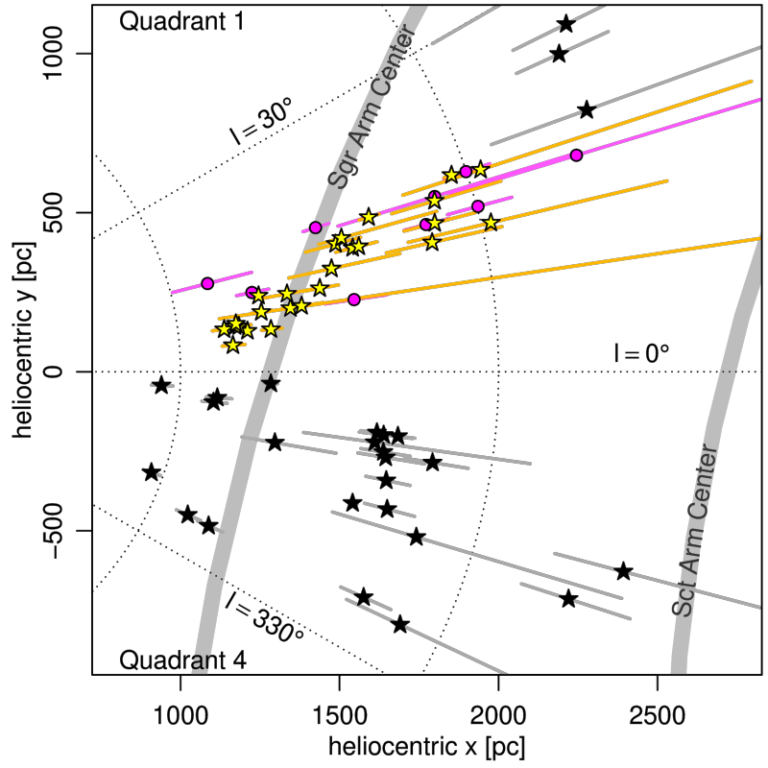
- Project 21, Projects
We map the 3D locations and velocities of star-forming regions in a segment of the Sagittarius Arm using young stellar objects (YSOs) from the Spitzer/IRAC Candidate YSO (SPICY) catalog to compare their distribution to models of the arm. Distances and velocities for these objects are derived from Gaia EDR3 astrometry and molecular line surveys. We infer parallaxes and proper motions for spatially clustered groups of YSOs and estimate their radial velocities from the velocities of spatially associated molecular clouds. The observed 56◦ pitch angle is remarkably high for a segment of the Sagittarius Arm. We discuss possible interpretations of this feature as a substructure within the lower pitch angle Sagittarius Arm, as a spur, or as an isolated structure.

- Project 20, Projects
Dawn of Stars tells the story of how stars are formed. Most stars are born in groups which are truly stellar nurseries composed by clouds of dust and gas. This birth process is full of episodes, some of which are represented musically in the four parts of this piece. This was the first art-related project to be developed by COIN, in March 2021, in collaboration with Rodrigo Roriz Teodoro, as part of his graduation project to obtain the degree of Master in music composition awarded by the Marshall University (USA).

- Project 19, Projects
We present ~120,000 candidate young stellar objects (YSOs) based on surveys of the Galactic midplane between l ∼ 255° and 110°, including the GLIMPSE I, II, and 3D, Vela-Carina, Cygnus X, and SMOG surveys (613 square degrees), augmented by near-infrared catalogs. We employed a classification scheme that uses the flexibility of a tailored statistical learning method and curated YSO datasets to take full advantage of IRAC’s spatial resolution and sensitivity in the mid-infrared ∼3–9 μm range. We also identify areas of IRAC color space associated with objects with strong silicate absorption or polycyclic aromatic hydrocarbon emission. Spatial distributions and variability properties help corroborate the youthful nature of our sample.
- Project 18, Projects
The Recommendation System for Spectroscopic follow-up (RESSPECT) project aims to enable the construction of optimized training samples for the Rubin Observatory Legacy Survey of Space and Time (LSST), taking into account a realistic description of the astronomical data environment. In this work, we test the robustness of active learning techniques in a realistic simulated astronomical data scenario. Our experiment takes into account the evolution of training and pool samples, different costs per object, and two different sources of budget. Results show that traditional active learning strategies significantly outperform random sampling.

- Project 17, Projects
Astrometric detection involves a precise measurement of stellar positions, and is widely regarded as the leading concept presently ready to find earth-mass planets in temperate orbits around nearby sun-like stars. The TOLIMAN space telescope is a low-cost, agile mission concept dedicated to narrow-angle astrometric monitoring of bright binary stars.In this paper we demonstrate that a Deep Convolutional Auto-Encoder is able to detected signals from simplified simulations of the TOLIMAN data and we present the full experimental pipeline to recreate out experiments from the simulations to the signal analysis.
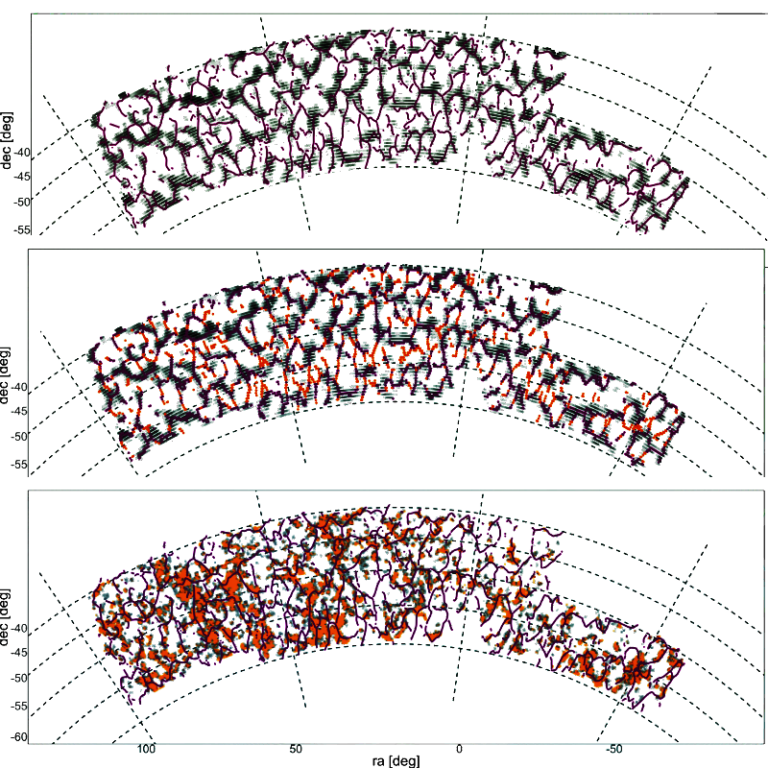
- Project 16, Projects
Cosmic voids play an important role in our attempt to model the large-scale structure of the Universe. In this paper, we apply it to 2D weak-lensing mass density maps to identify curvilinear filamentary structures. Our results demonstrate the viability of ridge estimation as a precursor for denoising weak lensing quantities to recover the large-scale structure, paving the way for a more versatile and effective search for troughs.